
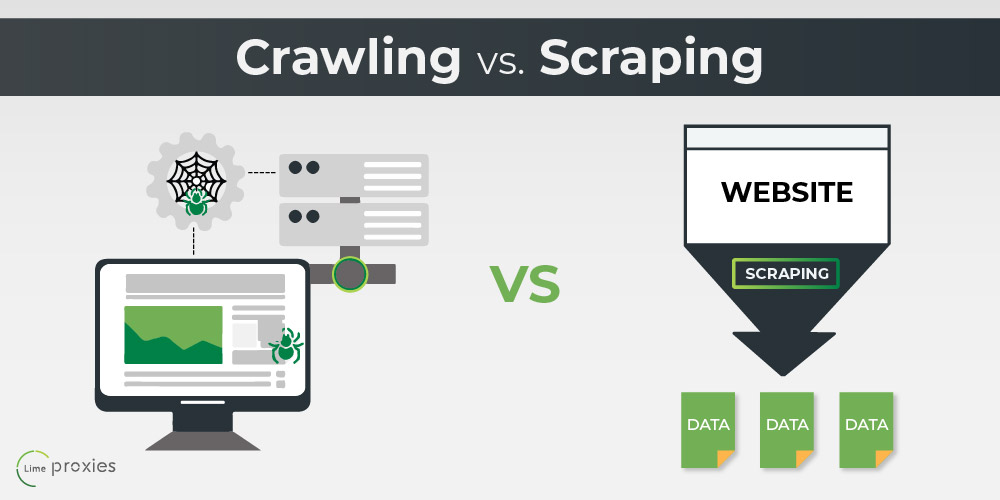
There are many ways to gain information or data from the internet. Of those many ways, two of the most popular ones are namely web crawling (or data crawling) and data scraping (or web scraping). Although you might often hear people using the terms almost interchangeably, the reality is far from this misconception.
While both web crawling and data scraping are essential methods of retrieving data, the information needed and the processes involved in the respective methods are different in several ways. Whereas scraping is preferred in some cases, crawling is the go-to option in others. You can opt for either, depending on what kind of information you’re looking to dig up.
However, in order to decide which method is best suited for your needs, it’s crucial to understand them individually, and then make an informed decision post your evaluation. Let us first explore what data crawling and data scraping entail.
Post Quick Links
Jump straight to the section of the post you want to read:
WEB CRAWLING - CRAWLING VS SCRAPING
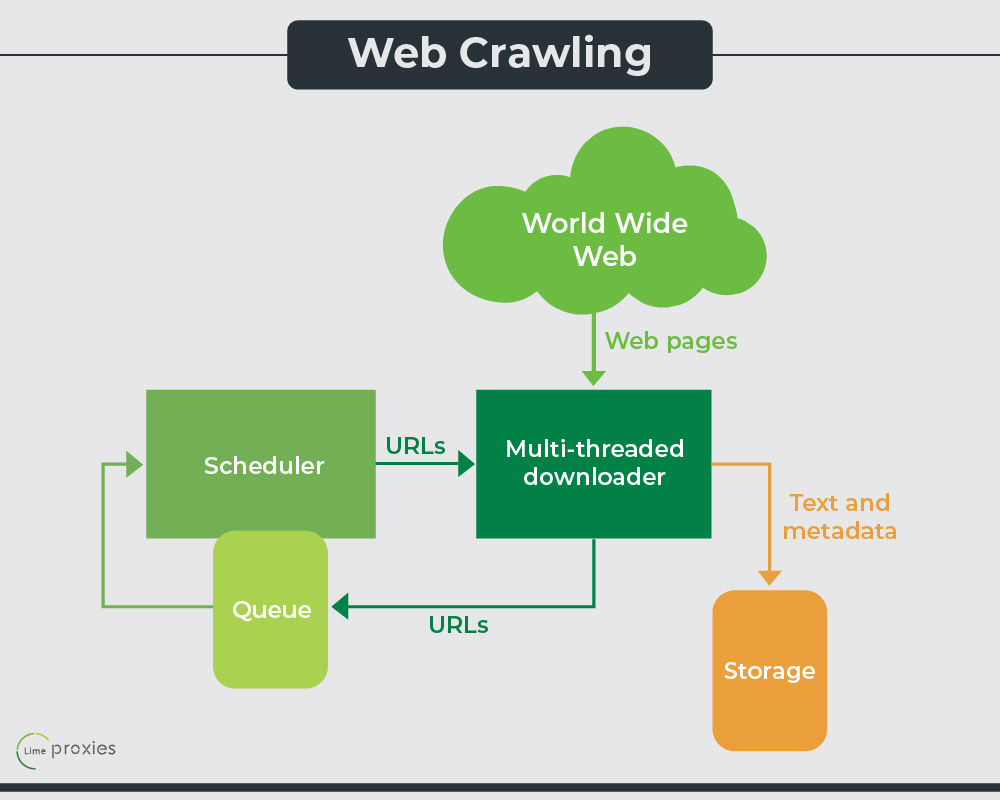
Web crawling can be defined as the process of hunting down information on the World Wide Web, adding all the compiled words found in a document to the database, and then proceeding to follow all the hyperlinks and indexes and adding them to the database as well. This process is performed by “web spiders” or “bots”.
A web crawler is an internet bot or a program that assists in web indexing. It browses through the internet in a systematic manner and looks up elements such as the keywords in each page, the kind of content it contains, the links, and so on. After this, it gathers all this combined information and returns it to the search engine. This is the simplest way of explaining the method of web crawling.
Web crawlers follow instructions based on an algorithm. Not only do they scan through pages, collecting and indexing information, they also pursue links to relevant pages. As they’re unaware of the difference, they often pull out duplicate information from a post that may have been plagiarised from a different source. Additionally, crawlers help in checking links and validating HTML codes. Web crawlers also have other names such as automatic indexers and robots. Some examples of web crawling services are Google and Bing.
QUALITIES OF A WEB CRAWLER
Web crawlers crowd the market in huge numbers. Their usability varies in degrees, and you can select from the ones available, depending on whichever matches your criteria for data requirement the most. However, only a few manage to make a name in the data industry, the reason being that the job of an efficient web crawler is not as easy one.
Also Read: How to scrape a website without getting blocked or misled?
The process of web crawling is evolving with easy passing day, and with the presence of numerous formats, codes, and languages, web crawling is a job tougher than ever. Here are a few qualities a productive web crawler should possess:
- Just like every organisation has its own hierarchy, similarly, a well-defined architecture must exist among web crawlers for them to function smoothly. Two of the most basic requirements of a web crawler are speed and efficiency. The gearman model should be applied on the web crawlers, consisting of supervisor sub crawlers and multiple worker crawlers. Supervisor crawlers are responsible for managing the worker crawlers who work on the same link, thereby aiding in speeding up the data crawling process per link. A dependable web crawling system prevents the loss of any data retrieved by the supervisor crawlers. Thus, it’s imperative to create a backup storage support system for all the supervisor crawlers, without having to depend on a single point of data management so that the web crawling is completed authentically.
- Intelligent recrawling becomes essential in the field of web crawling, as it’s used by various clients searching for relevant data. For example, imagine there’s a client from publishing who wishes to know the title, author name, publishing date, and price of each book. This is an arduous task since there are innumerable genres, publishers, and categories and they all get updated at different frequencies on the respective websites. Therefore, the development of intelligent crawlers is pivotal to analyze at what frequency do the pages get updated on the targeted websites.
- Scalability of a data crawling system is yet another significant factor to test out before launching it. With the ever-growing amount of data files and documents, your crawling system accommodates storage and extensibility in abundance. Each page has over 100 links and about 10-100 kb of textual data, and the space it takes to fetch the data from each page is close to 350kb. Multiplying that with over 400 billion pages comes to 140 petabytes of data per crawl. Hence, it’s a wise decision for your crawler to compress the data before fetching it.
- It’s of paramount importance that your web crawler is language neutral, as a lot of the data available for business insights and analytical conclusions exist in several languages. Adopting a multilingual approach will allow the users to request for data in any language, thereby enabling them to make informed business decisions concluded from the particulars provided by your data crawling system.
- Polite and ethical data crawlers are always preferred over badly timed or poorly structured ones in order to avoid denial-of-service attacks. This is why certain webpages have crawling restrictions to regulate their crawling process.
DATA SCRAPING
Data scraping implies finding the right data and extracting it from the page. Scraping doesn’t necessarily mean deriving the data from the web, because it can be obtained from any place. This includes a variety of sources, including storage devices, spreadsheets, etc. Since data scraping is applicable in a broader sense, it doesn’t have to be limited to a webpage or the internet.
Data scraping is particularly beneficial to extract data that is otherwise difficult to reach. Data scraping services can also carry out certain tasks that data crawling services are unable to, such as JavaScript executing, submitting data forms, and disobeying robots. Web scraping, of course, is linked to data scraping, as the former refers to a technique of extracting data from websites in particular.
Scraper bots conduct the process of web scraping. Firstly, the scraper bot sends out an HTTP GET request to a specific website. Once it receives a response from the website, it then dissects and analyses the HTML document for a specific pattern of data. After the extraction of the data, it is then converted into the format preferred by the author of the scraper bot.
Also Read: HOW WEB SCRAPING CAN HELP YOU GET AHEAD IN YOUR MARKET?
FUNCTIONS OF A SCRAPER BOT
There are many purposes behind designing a scraper bot. Some of them are as follows:
1. Content Scraping: This category of scraping is used to duplicate the particular advantage of a certain product or service that relies on content. For example, if a product relies on reviews, a rival page could scrape all the review content from their competitor and replicate the content on their website pretending its original.
2. Contact Scraping: Websites often contain contact details like email addresses, phone numbers, location, and the like. Scrapers can combine these details for bulk mailing lists or even social engineering attempts. This is often used by spammers and scammers to locate new targets.
3. Price Scraping: Your competitors can use your pricing data to their own advantage. By discovering details regarding your pricing, they can formulate features of their own to drive traffic or attention to their page.
DIFFERENCES BETWEEN DATA CRAWLING AND DATA SCRAPING
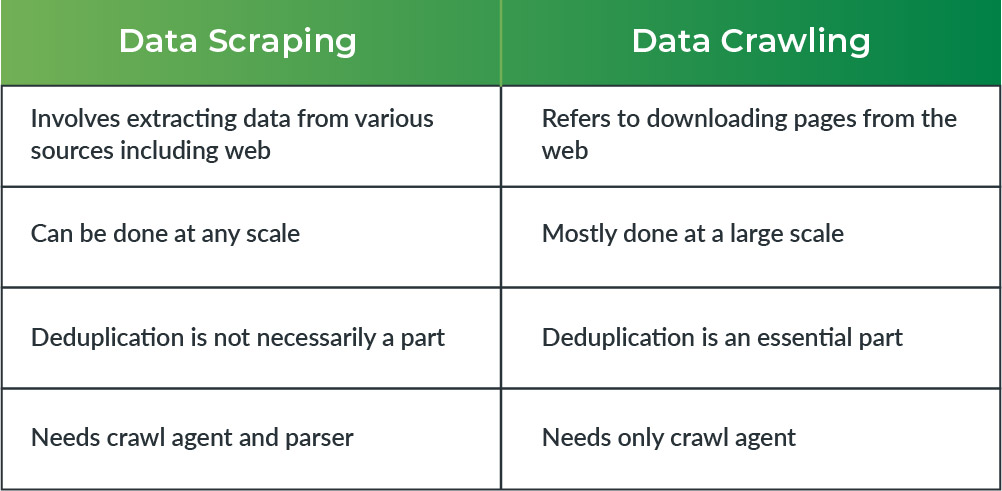
Regardless of what people think, there are quite a few differences between data crawling and data scraping. While some are subtle, the others are pretty big and evident. Listed below are some of the major differences between the two methods:
- The first and most important difference between the two is that while data crawling can only be done with information received from the web, data scraping does not always have to be associated with the web or the internet. Scraping can even be performed by extracting information from a database, a local machine, or a mere “Save as” link on a page. Therefore, while crawling is limited to the web, scraping has a broader spectrum.
- There is an abundance of information out there on the internet. More often that not, this information gets duplicated, and multiple pages end up having the same data. While the bots don’t have any means of identifying this duplicate information, getting rid of the same data is necessary. Therefore, data de-duplication becomes a component of web crawling. Data scraping, on the other hand, doesn’t necessarily involve data de-duplication.
- Web crawling is a more nuanced and complex process as compared to data scraping. Scrapers don’t have to worry about being polite or following any ethical rules. Crawlers, though, have to make sure that they are polite to the servers. They have to operate in a manner such that they don’t offend the servers, and have to be dexterous enough to extract all the information required.
- In web crawling, you have to ensure that the different web crawlers being employed to crawl different websites don’t clash at any given point of time. However, in data scraping, one need not worry about any such conflicts.
Also Read: THE TOP 5 GUIDELINES FOR SCRAPING AMAZON SAFELY>
Both scraping and crawling are data extraction methods that have been around for a very long time. Depending on your business or the kind of service you’re looking to get, you can opt for either of the two. It’s essential to understand that while they might appear the same on the surface, the steps involved are pretty different. Therefore, research the processes carefully before you decide on the one that best suits your requirements.


About the author
Rachael Chapman
A Complete Gamer and a Tech Geek. Brings out all her thoughts and Love in Writing Techie Blogs.
Related Articles
Top 10 CRM Tools For SaaS and Tech Startups
The Customer Relationship Management market grew over 12.3%. According to the latest statistics – Microsoft, SAP, Oracle, and Salesforce provides the best CRM system
Top 10 Mistakes to Avoid In SEO
Beginners make SEO mistakes because they don’t understand SEO best practices, or because they are not aware. Top 10 SEO Mistakes to Avoid.