Web Scraping Best Practices
Data in today’s world is available throughout the internet. Most often it is not possible to be online to collect the information. Also, the option only allows us to view the data. What if there is a need to transform and blend the information with another set of data? The process of manually extracting data from websites is a tedious and cumbersome process.
Web Scraping is a technique that allows its users to extract a large amount of data from the web. Data found on the web can only be viewed when online. The technique of web scraping enables us to extract large data for personal use. This data is stored as a local file in your system or as a spreadsheet.
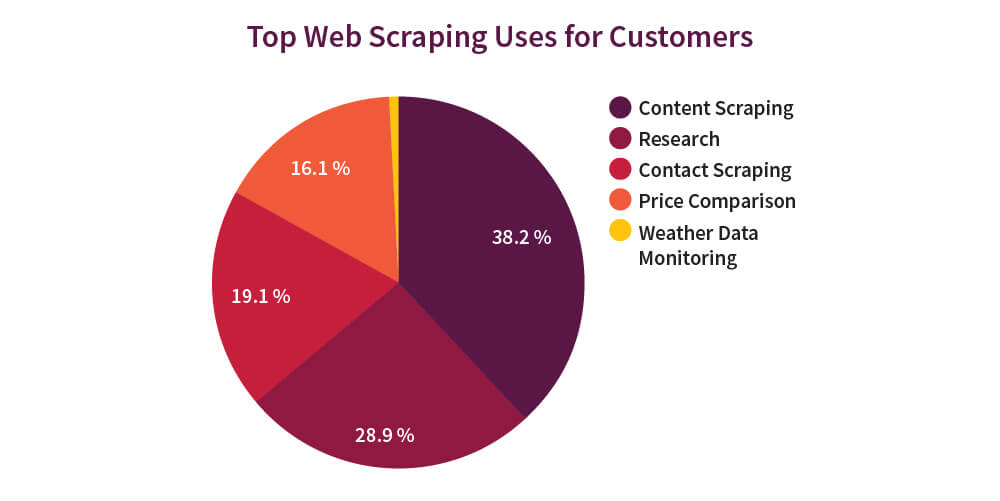
The process of web scraping can be done either by bots or humans. Bots are capable of performing tasks a lot faster than humans. But, using bots can also cause a lot of loss in revenue for the victims. About 37.9% of web traffic is due to bots. Distil Networks curated a list from Scraping Hub, Diffbot, and ScreenScraper on why web scraping is done and this is the result.
Proxies play a crucial role when it comes to web scraping. The main advantage of using a proxy is that it allows you to hide your machine’s IP address. This way when you send requests, the target site will see the requests coming in from a proxy IP and not your original IP.
LimeProxies is the best place to find premium proxies. It works great with high-performance software and has a fully automated control panel that enables easy management.
Here is what Lime Proxies has to offer you:
Why is data scrapped?
There are multiple use cases for web scraping. Here are a few:
- To get lead generation for Sales
- Get real estate listings
- Compare price listing from various sites
- Better access to a company’s data
- Marketing automation
- Data Enrichment
- Monitoring flight schedules
- Identify best-selling products from a website
- Building sports data repository via web crawling
- Aggregating geographically-sparse feeds
- Twitter Scraping for Sentiment Analysis
- Finance data in near-real time
- Scraping Bank Websites to Power Credit Card Comparison Portal
- Extracting large-scale job data from popular job portals
- Building an extensive and high volume car database
How does scraping happen?
Web scraping generally happens using spiders in HTML. Spiders are language-specific classes that will define how a web page should be scraped. This includes how to perform the crawl the links and the information on how to extract structured data from these pages. In other words, Spiders allow you to define custom behavior for crawling and parsing pages for a particular site, group of sites or a group of use cases.
This is what happens in the back end. In the front end, the web scraping software that you have installed will automatically load and extract data based on the spider class, this can be multiple pages from the same website, or it can span across different pages to get the information. The information can then be downloaded in a single click.
Techniques to web Scraping
1 . Try Local Cache
A local cache is a data that is downloaded to your system when you visit a site. This is a subset of the original data from the website. When scrubbing large websites for data, it is easier and safe to use the cache that is already available in your system. By doing this the user doesn’t have to reload the site again. This is a great option in cases where the web page is expected during scrubbing. You need to use a file caching mechanism system like MySQL to extract and store the information.
2. Optimize and Prioritize Requests
Most of the sites today deploy tools to track crawling on a site. There are high chances that you will be classifies as DOS and blocked if the requests are not sent from the same IP address. Denial of service attack is generally where multiple requests are sent to the server from different IP addresses, most of which would return null. But, the server would not be able to find a return address to send the message. This will stall the service for some time. In such cases, the website will block the information under a DOS attack. Therefore, a careful examination of the requests is necessary. You also need to prioritize and chain the requests properly. It is best if it is done one after the other and not dumped in altogether. An easy way to channel the requests is to determine the ART (average response time) of the site first and then send the requests accordingly.
3. Tabulate the URL
You always need to know the URLs that you have crawled. Therefore it is a best practice to store them in a table. This will be of great help in case the crawler collapses, you will have a list of links to help you re-instantiate and save time.
4. Do it in segments
Segmentation always helps. Divide your links into short segments. This makes it simple to account and plan your bandwidth accordingly. For example, let us say you have a site, you can logically group the process of scraping into two, 1. To assimilate the links and 2. To download the content.
5. Plan Navigation
It does not make sense to crawl each and every link available on a page. It takes a lot of time and also there are high chances that most of the links out there are useless for you. Plan your navigation in such a way that the pages that are most required are crawled first. It might seem rosy to go out to every link and check for information, but the cost of it would be a lot of time, bandwidth and storage.
6. Check for API
Today almost all sites allow users to fetch their data willingly. If the site that you are accessing provides you to fetch data, you don’t have to scrap it. All that you need to do is follow their documentation and get your developer to do it for you. Also, it makes sense to first check their terms and conditions page for no crawling restrictions.
7. JSON
Just in case the site that you are scraping does not provide support for API and you still have to do it, check if they offer support for JSON. JSON works great for pages with shorter loading times.
Now that you have figured it out, all that you have to do id press f12 which will open the developer's tool window and reload the page. Next, go to the sources tab and find pages that end with.JSON. Open the URLs in the new tab to display the JSON with the data.
8. Be Authentic
Website owners will get outraged if they find out that you are scouring their data. Therefore always scrape the data with a header that has your personal information such as your name or email address.
Make sure that you provide adequate information for the website owners to contact you in case of a need. You might want their information, but doing it without leaving back your personal information might come off as illegal and rude. Stay nice while scraping someone’s data.
9. Use Proxies
Large websites have ways to detect the IP address from which the requests come in. If there are multiple requests from the same IP then it denotes that there is something fishy about it, which mostly means that someone is trying to frisk their data or content. Therefore the websites, to be safe, will block the IP address. This makes it impossible for you to get scrub data from multiple pages within a short span.
In order to avoid this, you can use multiple proxy servers. Proxy servers will mask your original IP address. Therefore the target site will see requests from multiple IP addresses, giving it a human-like behavior.
How can websites detect web scraping?
Websites have their own methods to identify scrappers. Some install apps like honey pots that identify and block scrapers. But, these are specific cases. In general, this is how most websites identify scraping. Make sure that you do not follow this to go unidentified.
- Unusual traffic or download rate from a single address within a short time
- Humans do not perform the same tasks on and on, on a website. Any unhuman behavior can be easily identified
- Honey pots are invisible fake links that are not visible for humans but only to a spider. When the spider crawls the links, it sets an alarm and alerts the site.
Hope you found this blog useful.
LimeProxies offers premium proxy services. Looking out to test Web Scraping with Proxies?

