

A proxy server acts as a tunnel to get things done without having too much of an attention on you. It is like your gateway to the internet with a mask.
It is like a whole new level between you, who is the end user and the internet. Proxies servers are designed to provide security and privacy depending on the use case.
When using a proxy server, it channels on flow of internet traffic and gets you to the URL requested. The response to this request is also through the same tunnel and then the data that you need is provided to you.
So, if this is the use of a Proxy Server, why do you need one? Why can’t this be done normally?
Because, proxies do more that that, they act as a firewall between the website and you. They provide shared connections, clear cache data to speed requests and filter the data. It helps keep users protected from the harmful stuff on the internet by providing the highest level of privacy and security.
Post Quick Links
Jump straight to the section of the post you want to read:
OPERATING PROXY SERVERS
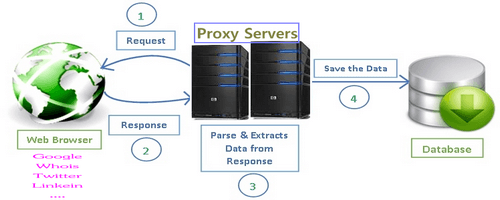
Every device connected to the internet will have a unique IP address. This is something like how your house has a physical address, think of the same thing in the virtual world. The data that you need is requested from this address, now, when the information is processed, it is returned back to the same address.
A proxy server in layman terms is like another computer with its own IP address that can be accessed from your computer. Every request that you send first goes to the proxy server. Now this server requests on your behalf and gets the response. Once it gets the response it forwards it you, and you can access the webpage.
So, what actually happens is when the proxy server sends the data as web request, it changes the request a little, but you still will get to see what is expected. The server changes the IP address, so that the web server does not know where you are accessing the data from. It encrypts your data in such a way that it is unreadable during transit.
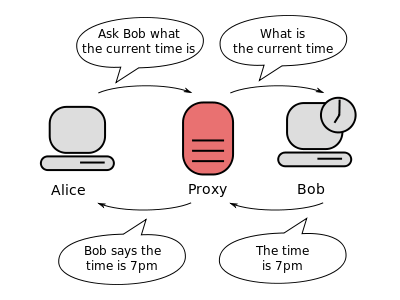
USES OF A PROXY SERVER

Using a Proxy Server carters a wide range of use cases for both the individual as well as the organization.
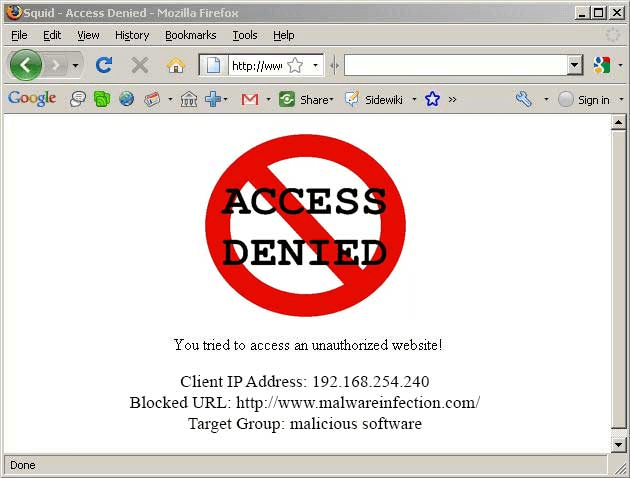
1 . TO CONTROL INTERNET USAGE
Source- infosightinc.com
Companies would often want to monitor what their employees search over the internet. They’d want to restrict the accessibility of certain sites which they think might reduce their productivity. Similarly parents might want to control what their kids access on the internet. Companies use proxy to deny access and redirect to you a page asking you to refrain from checking out the mentioned site. They can also keep track of the time you spend cyberloafing.
2. BANDWIDTH SAVINGS
Source - Paessler AG
Organizations on the whole get a better performance using a good proxy server. Proxy servers tend to save a copy of the website (cache). Therefore when you try to access a website, the proxy sever will check if the saved copy is the recent copy and then send it to you. Let us say there are multiple employees trying to access your company’s website at the same time, the proxy sever will have to access the website only once and then save the cipy locally. It will then send that information to any employee trying to access the page. This improves the performance.
3. PRIVACY
Proxy serves have the capability of hiding who sent the request. Proxies are capable of hiding who sent the original request. The destination server will not the original source of the request and helps in keeping things private.
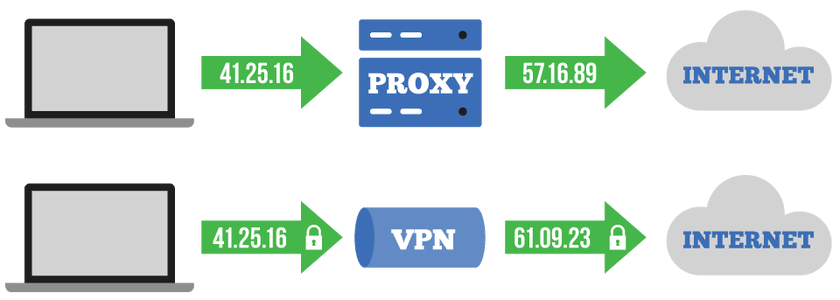
4. SECURITY
Proxy servers allows you to encrypt the web requests such that you can keep your transactions safe. This prevents malware sites from accessing your information. Organizations can also set up a VPN using a proxy to allow employees access the internet only via the company proxy. This allows the company to control who access the data while allowing the employees to login from a remote location.
Source - proxy-firewall.com
5. WEB SCRAPING USING A PROXY SERVER
Using a proxy server companies can access restricted data. It is a technique that allows its users to extract a large amount of data from the web. Data found on the web can only be viewed when online. The technique of web scraping enables us to extract large data for personal use. This data is stored as a local file in your system or as a spreadsheet.
The process of web scraping can be done either by bots or humans. Bots are capable of performing tasks a lot faster than humans. But, using bots can also cause a lot of loss in revenue for the victims. About 37.9% of web traffic is due to bots. Distil Networks curated a list from Scraping Hub, Diffbot, and ScreenScraper on why web scraping is done and this is the result. Proxies play a crucial role when it comes to web scraping. The main advantage of using a proxy is that it allows you to hide your machine’s IP address. This way when you send requests, the target site will see the requests coming in from a proxy IP and not your original IP.
Source - Kimonolabs
TYPES OF PROXY SERVERS

There are different types of proxy servers that you can configure. Each of it addresses a different use case. You need to know what problem you are trying to solve and configure the correct proxy.
1 . TRANSPARENT PROXY
A transparent proxy informs the website that the system is trying to access the website via a proxy and still pass the information to the server. Schools, libraries and businesses often use this for content filtering.
2. ANONYMOUS PROXY
An anonymous proxy is when the proxy will identify itself as one but will refrain from sending that information to the web server. This will help in preventing data theft. Companies generally pick up the customers’ location information and show the relevant business information to them. If you do not want companies to access this information of yours you can use an anonymous proxy.
3. DISTORTING PROXY
A distorting proxy passes an incorrect IP address and yet identify itself as a proxy. This is similar to an anonymous proxy, by showing a false IP, it makes it difficult for companies to identify the original location from which you are accessing the site.
4. HIGH ANONYMITY PROXY
High Anonymity proxy servers keep changing the IP address of the web server making it difficult to identify the source and destination of the traffic. It is the most secure way to read the internet.
WEB SCRAPING
Web scraping generally happens using spiders in HTML. Spiders are language-specific classes that will define how a web page should be scraped. This includes how to perform the crawl the links and the information on how to extract structured data from these pages. In other words, Spiders allow you to define custom behavior for crawling and parsing pages for a particular site, group of sites or a group of use cases.
This is what happens in the back end. In the front end, the web scraping software that you have installed will automatically load and extract data based on the spider class, this can be multiple pages from the same website, or it can span across different pages to get the information. The information can then be downloaded in a single click.
Source - bestpaidproxies
PROXIES FROM WEB SCRAPING
IP banning is a common issue when you want to scrap the web for content. The website that you are targeting might have sensitive information that they’d not want you to access or they may simply not like you accessing the exclusive information that they have. Therefore, when they find out that you are trying to copy their data, they may end up banning your IP address.

Source - scraping.pro
When your IP address is banned, it will affect your business as the flow that you usually use will not work anymore. Inorder to solve these issues, you can use a proxy server in Scrapy.
HOW CAN WEBSITES DETECT WEB SCRAPING?
Websites have their own methods to identify scrappers. Some install apps like honey pots that identify and block scrapers. But, these are specific cases. In general, this is how most websites identify scraping. Make sure that you do not follow this to go unidentified.
1 . Unusual traffic or download rate from a single address within a short time
- Humans do not perform the same tasks on and on, on a website. Any unhuman behavior can be easily identified
3. Honey pots are invisible fake links that are not visible for humans but only to a spider. When the spider crawls the links, it sets an alarm and alerts the site.
SETTING UP PROXIES
Setting up a proxy in Scrapy is extremely easy. There are two ways by which you can implement this functionality.
1 . Using Request Parameters
- Creating a custom Middleware
1 . USING REQUEST PARAMETERS
Generally you just pass an URL and target a callback function when you are using a Scrappy. But, if you are looking at using a specific proxy for a particular Url, then it is possible if you ass a meta tag. Consider this example:
def start_requests(self):
for url in self.start_urls:
return Request(url=url, callback=self.parse,
headers={"User-Agent": "My UserAgent"},
meta={"proxy": "http://192.168.1.1:8050"})
There is a middleware in the Scrapy called Proxy Middleware which passes the request object and sets it up.
2. CREATE A CUSTOM MIDDLEWARE
In case you do not want to use the middleware that is already provided, the next option that you have is to create a custom middleware. The process of passing this middleware is similar to the one above:
from w3lib.http import basic_auth_header
class CustomProxyMiddleware(object):
def process_request(self, request, spider):
request.meta[“proxy”] = "http://192.168.1.1:8050"
request.headers[“Proxy-Authorization”] =
basic_auth_header(“<proxy_user>”, “<proxy_pass>”)
In the above code we pass the necessary authentication
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomProxyMiddleware': 350,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 400,
}
TESTING A PROXY
It is important that you try the proxy before you use it. You can test it on a test site. If the Site shows you the IP address of your proxy and not the actual IP then it is working.
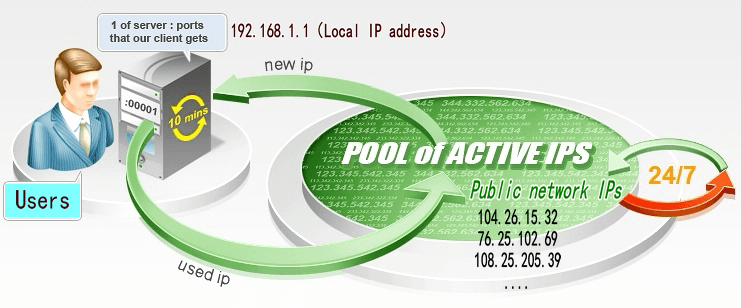
ROTATING PROXIES
Is it not possible to ban a proxy?
Well, no, you can ban a Proxy IP as well. But, fortunately there is a solution for that. The key is to rotate IPs. When you rotate a bunch of IP address, they randomly pick an address and request for the web page.

Source: Smart Proxy
If it succeeds then the page is displayed. If it is banned then another IP is picked from the bundle. Managing this manually requires a lot of effort. But, if you install a Scrapy rotating proxy then you can automate this effort.
Source: best paid proxies


About the author
Rachael Chapman
A Complete Gamer and a Tech Geek. Brings out all her thoughts and Love in Writing Techie Blogs.
Related Articles
The Ultimate Guide to Buy Private Proxies
Proxies are a great tool to enhance internet users’ security and privacy. When proxies first emerged, it was viewed in a negative light as some thought that it was used only by people hiding their suspicious and even criminal acts.
Tips To Become A Great IT Security Manager
IT security or Security of Information Technology – it is a very crucial concern nowadays. With the increase in technological development, there is an increase in the number of confidential documents with IT companies’ and also there is an increase in online thefts.